The Concept of Reproducible-ML¶
Introduction¶
Machine learning (ML) is a field which has become a very important part of today’s research. The algorithms as well as the availability of large GPU/CPU clusters are responsible for the widespread success that were and will be achieved within this field of research.
A big part of this research normally includes a large number of experiments with a lot of different hyperparamter settings. Keeping track of all this parameters with the corresponding results is a challenge every researcher in this field is facing. Due to common problems, such as time pressure this important issue is not given much attention while developing code. Using Reproducible-ML you do not have to think about that, since we use Sacred [14] , which is a great infrastructure for computational research which provides a setup for tracking computational experiments. Sacred is very easy to use, does not need a lot of extra code and comes with a very nice web-based interface called Sacredboard and a tool for hyperparamter tuning called Labwatch.
Another important issue of machine learning frameworks is the trade-off between flexibility vs. simplicity. As stated in Cheng et al. [8], there is a natural tension between flexibility on one hand, and simplicity on the other hand. According to Cheng et al. frameworks as in [6] achieve flexibility by low level operations (e.g. matmul, add, etc.), this requires the programmer to write a lot of code in a normal programming language to implement a model. This type of flexibility does not meet the requirements of simplicity and comes with another big drawback, namely code duplication. On the other end of the spectrum are model architectures in a domain-specific language (DSL) (e.g. [10]). These models clearly reach a high level of simplicity but when it comes to quickly adapt it to a specific problem they often fail. By integrating the TensorFlow Estimator [6], which is implemented on top of TensorFlow, in Reproducible-ML we hope to build a framework that is simple, flexible and does not suffer from the code duplication drawback.
In addition, Reproducible-ML uses the TensorFlow data import API [3] which enabled us to build an efficient data input pipeline from simple pieces. When for example randomly merging data into a batch or converting the data to binary file format we used this specific API.
By combining the Sacred package, TensorFlow and the TensorFlow Estimator module we hope to provide a framework which covers the whole machine learning pipeline from data input (e.g. images) to the desired output (e.g. prediction), with all the advantages of the different modules. We first give an overview over the typical components of such a pipeline. Then we show how to set up Reproducible-ML and run some first tests to check the setup (Getting Started with Reproducible-ML) before discussing the major components in detail (Components of Reproducible-ML). We then show how to use Reproducible-ML based on some experiments (Experiments) and finally there is a complete API documentation (API Documentation) in which all objects, functions and variables are documented.
Overview¶
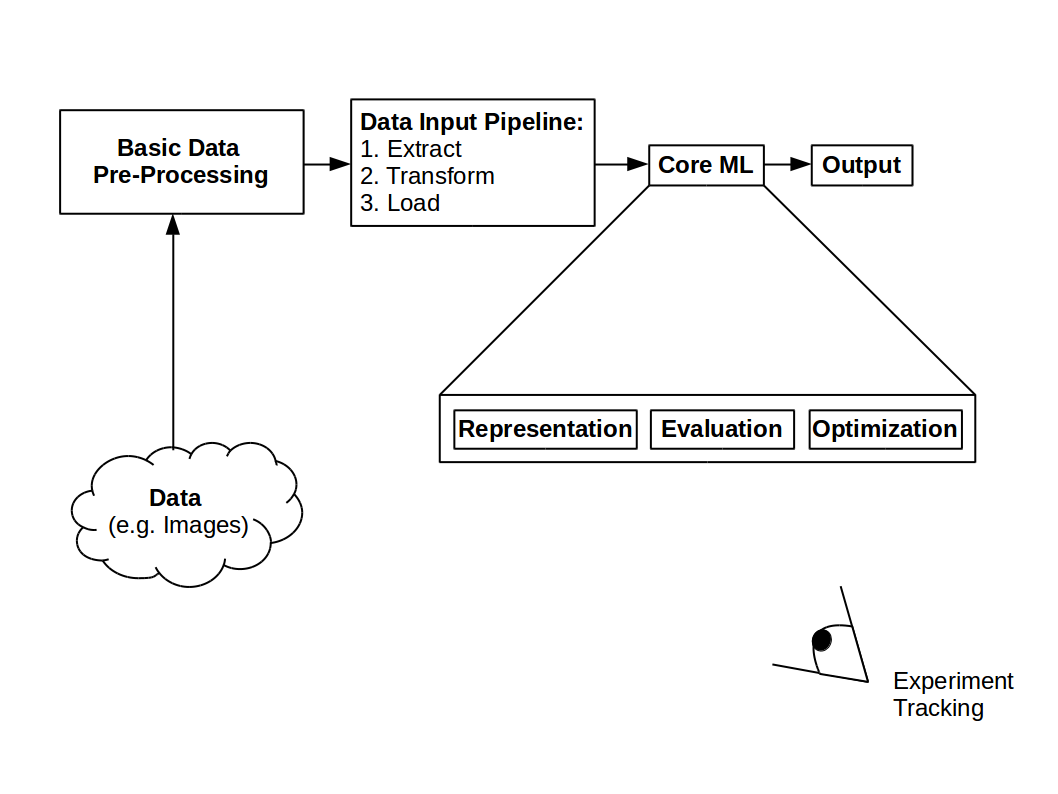
Machine learning pipeline overview
The access to a large amount of data is indispensable, therefore the first step for a working ML pipeline is fetching the data. For the simple case of handwritten digits [11] have a look at the Experiments on MNIST Database.
Basic Data Pre-Processing¶
Before entering the main ML pipeline, the data has to undergo a basic pre-processing. If this is not done with great care, the best ML algorithms will not perform better than random guessing. “Garbage in, garbage out” would be the fitting phrase.
Depending on the data set there are different reasons why basic pre-processing has to be done:
- The data may be flawed i.e. out-of-range, Not a Number, missing or impossible data combinations.
- The data may be stored in different data sets, different data types or in an inefficient way. Reorganizing and serializing has to be done.
- The data could be collected in a inconvenient or non regular manner.
- Images may need some basic filtering, smoothing, scaling or slicing (e.g. from 3D to 2D).
This list is by far not complete but it helps to get an idea of basic data pre-processing.
There are several ways to handle these problems and we will see how Reproducible-ML will tackle some of them. In addition you will see how to easily expand and adapt them. The following paragraph will include another more advanced pre-processing step.
Data Input Pipeline¶
According to [1] a typical ML data input pipeline can be formed as an extract, transform, load (ETL) process.
- Extract: Extract the data from its current location. Which can be local or remote.
- Transform: Within this step, the more advanced pre-processing steps will take place, such as image decompression, data augmentation, transformations, shuffling, batching etc.
- Load: Load the transformed data into the working device (e.g. GPU) where the core ML algorithm is executed.
How the input pipeline was implemented in Reproducible-ML, is described in Components of Reproducible-ML.
While working with GPUs, it is advantageous to perform the transformation steps on CPUs, while reserving the computational power of the GPUs for the more demanding ML calculations.
The Core of ML¶
Domingos states in his paper A Few Useful Things to Know About Machine Learning [12] that a learning process consists of combinations of the following three components:
1. Representation: This is also called hypothesis space of the learner. A hypothesis space is a set of functions in which we hope to find the underlying function of the data distribution, the so called target function. An example for a hyphothesis space would be the space of linear functions.
2. Evaluation: An evaluation function gives a feedback on how good the chosen representation is. This function is often called the objective function. Probably the most common evaluation function is the squared error function.
3. Optimization: At last, we need a method to search in our hypothesis space for the best scoring target function. An example of an optimization would be gradient descent which finds the minimum or maximum of the evaluation function
For a simple two class classification task the combination of the components could look as follows:
1. Representation: A hyperplane
2. Evaluation: Hinge loss
3. Optimization: Stochastic gradient descent with momentum
Output¶
Almost everything can be the output of a ML pipeline. In the case of classification it will be a class or some probabilities assigned to different classes, in the case of a generation it could be an image or an audio frequency or when considering an auto encoder, the output matches the input in the optimal case.
Of course, many other types for ML algorithms exists and many other important things have to be considered, such as generalization, overfitting, feature engineering and many more. But the knowledge about these things comes with experience and depends mainly on the data set present.
Reproducible-ML provides such a ML pipeline as described above. We tried to make it flexible and at the same time simple for easy adaption. Experiment tracking with Sacred and random seed settings help to get reproducible results. The way the data input is realized in Reproducible-ML brings an additional speed up. And last but not least, this documentation shall help every user to find its way around in a general ML framework. At this point we encourage you to proceed to Getting Started with Reproducible-ML and make yourself familiar with Reproducible-ML.